Generic cache system
Overview
GCache is a generic multilevel priority based cache system which is useful for allocating resources across RAM, GPU, disk, network etc.
Class documentation created using Doxyigen is available in the docs/html/ directory
A quick example might better explain the concept; see a more detailed example for source code and in depth comments. we want to implement a priority cache for our database of 10000 images. We will use 2 levels of caching, RAM and GPU while the images will be stored on disk.
- Each image is managed through a token which holds the pointer to the data and is used to assign a priority to the image.
- We subclass Cache to our RamCache and GpuCache and define function for loading from disk and uploading the texture to the GPU
- We can set priorities for the images according to our strategy.
- Before rendering the image we lock the token and unlock it when done
Design
GCache is designed for very frequent priority updates where the majority of resurces are involved. All the system is designed to minimize the computations required to change priorities and sorting them.

Token
Each resource is managed through a pointer to a subclass of Token<Priority>.
Token pointers are transferred between caches but never created or deleted by the cache system.
The user is responsible for storage of the tokens.
Adding tokens to the cache is done using the function Controller::addToken(Token *);
the tokens can be scheduled for removal using the function Token::remove() or be dropped
when the max number of tokens in the controller is reached
as set by Controller::setMaxTokens(int). Use Token::isInCache() to check
for actual removal.
Priority
The Token class is templated over a typename Priority which usually
it is a floating point number, but it can be anything sortable through Priority::operator<(const Priority &).
The goal of the cache system is to juggle resources around so to have the highest priority tokens in the higher cache.
Use function Token::setPriority(Priority) to set tokens priority; it does not require mutexing and it is
therefore vert fast. The change will take effect only upon a call to Controller::updatePriorities().
Each cache holds a double heap of Tokens (see architecture picture), 'sorted' accordingly to priority. A double heap is a data structure with similar properties to a heap but which allows quick extraction of both min and max element.
Priorities are sorted with a lazy approach, only when needed (usually when checking if a transfer should be performed. This results in the higher, smaller caches being sorted more frequently than the larger lower caches.
Caches
The user needs to subclass the Cache class and override the virtual functions get(Token *),
drop(Token *) and size(Token *). Each cache runs its own thread. Resource transfers (reading a file content, uploading a texture, etc)
are performed in that thread using blocking calls.
Cache are added to the controller using the function Controller::addCache(Cache *)
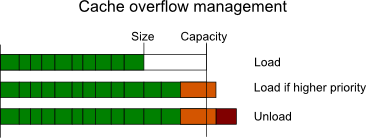
The GCache employs a nested cache model: if a resource is present in a cache is also present in all the lower ones, and thus each cache should have more capacity than the lower one. For sake of simplicity and performances each cache is allowed to overflow its capacity by at most one resource. (see picture)
Locking
Resources must be locked before use, to prevent cache threads to unload them while in use. An object can be locked
only if already loaded in the highest cache, otherwise the lock() function will return false.
Unlock allows the resource to be eventually dropped from the cache. Locks are recursive which means Tokens keep track
of how many time lock() have been called and release the resource only after unlock()
is called that many times.
Loking and unlocking costs basically zero (we are using QAtomicInt).
Minimal example
This is a minimal pseudo-code example, just to quickly cover the basis. For a real example, involving also sending resources to the GPU using a share context check the example/my_widget.h file.
class MyToken: public Token<float> {
public:
MyData *data;
GLUint texture;
};
class RamCache: public Cache<MyToken> {
public:
//return size of object. return -1 on error
int get(MyToken *token) { fread(someting into something); return 1; }
//return size of objecy, cannot fail
int drop(MyToken *token) { delete memory; return 1; }
int size(MyToken *token) { return 1; }
};
class GpuCache: public Cache<MyToken> {
public:
int get(MyToken *token) { glCreate + glTexture;return 1; }
int drop(MyToken *token) { glDelete; return 1; }
int size(MyToken *token) { return 1; }
};
//generate tokens
vector<MyToken> tokens;
for(int i = 0; i < 10000; i++)
tokens.push_back(MyToken(i));
//create ram and gpu caches
RamCache ram;
ram.setCapacity(5000);
GpuCache gpu;
gpu.setCapacity(1000);
//create controller and add caches
Controller<MyToken> controller;
controller.addCache(&ram);
controller.addCache(&gpu);
//tell controller about tokens and start
for(int i = 0; i < tokens.size(); i++) {
tokens[i].setPriority(rand()/((double)RAND_MAX));
controller.addToken(&tokens[i]);
}
controller.start();
//change priorities
for(int i = 0; i < tokens.size(); i++)
tokens[i].setPriority(rand());
controller.updatePriorities();
//lock and use the tokens
for(int i = 0; i < tokens.size(); i++) {
bool success = tokens[i].lock();
if(success) {
//use the token as you see fit
tokens[i].unlock();
}
}