22 KiB
Internals
This section records some design and implementation details.
[TOC]
Architecture
SAX and DOM
The basic relationships of SAX and DOM is shown in the following UML diagram.
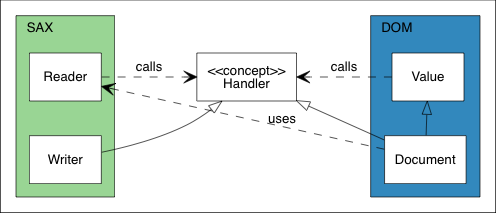
The core of the relationship is the Handler concept.
From the SAX side, Reader parses a JSON from a stream and
publish events to a Handler. Writer implements
the Handler concept to handle the same set of events. From
the DOM side, Document implements the Handler
concept to build a DOM according to the events. Value
supports a Value::Accept(Handler&) function, which
traverses the DOM to publish events.
With this design, SAX is not dependent on DOM. Even
Reader and Writer have no dependencies between
them. This provides flexibility to chain event publisher and handlers.
Besides, Value does not depends on SAX as well. So, in
addition to stringify a DOM to JSON, user may also stringify it to a XML
writer, or do anything else.
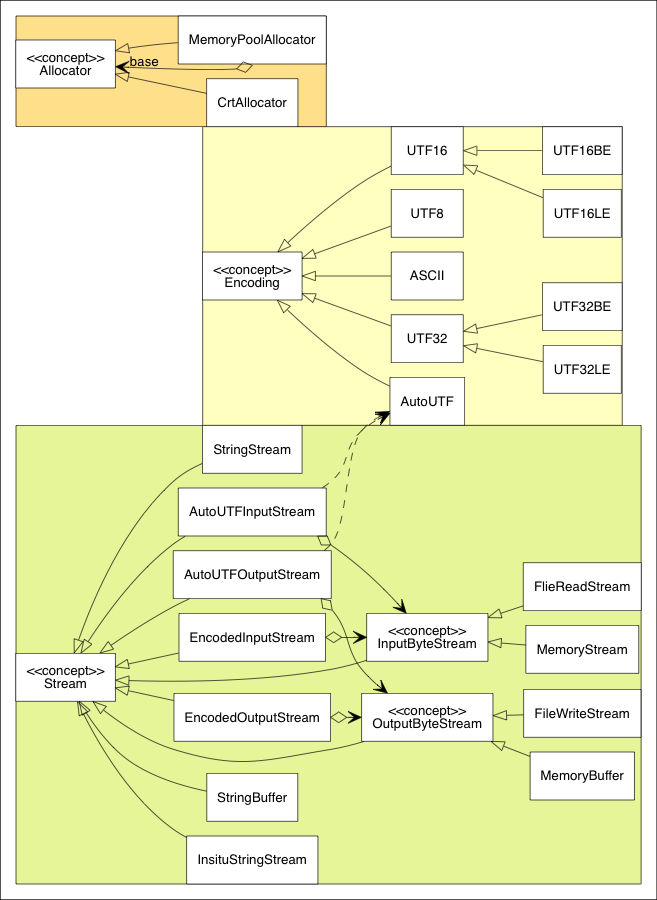
Utility Classes
Both SAX and DOM APIs depends on 3 additional concepts:
Allocator, Encoding and Stream.
Their inheritance hierarchy is shown as below.
Value
Value (actually a typedef of
GenericValue<UTF8<>>) is the core of DOM API.
This section describes the design of it.
Data Layout
Value is a variant type. In
RapidJSON’s context, an instance of Value can contain 1 of
6 JSON value types. This is possible by using union. Each
Value contains two members: union Data data_
and aunsigned flags_. The flags_ indicates the
JSON type, and also additional information.
The following tables show the data layout of each type. The 32-bit/64-bit columns indicates the size of the field in bytes.
| Null | 32-bit | 64-bit | |
|---|---|---|---|
| (unused) | 4 | 8 | |
| (unused) | 4 | 4 | |
| (unused) | 4 | 4 | |
unsigned flags_ |
kNullType kNullFlag |
4 | 4 |
| Bool | 32-bit | 64-bit | |
|---|---|---|---|
| (unused) | 4 | 8 | |
| (unused) | 4 | 4 | |
| (unused) | 4 | 4 | |
unsigned flags_ |
kBoolType (either kTrueFlag or
kFalseFlag) |
4 | 4 |
| String | 32-bit | 64-bit | |
|---|---|---|---|
Ch* str |
Pointer to the string (may own) | 4 | 8 |
SizeType length |
Length of string | 4 | 4 |
| (unused) | 4 | 4 | |
unsigned flags_ |
kStringType kStringFlag ... |
4 | 4 |
| Object | 32-bit | 64-bit | |
|---|---|---|---|
Member* members |
Pointer to array of members (owned) | 4 | 8 |
SizeType size |
Number of members | 4 | 4 |
SizeType capacity |
Capacity of members | 4 | 4 |
unsigned flags_ |
kObjectType kObjectFlag |
4 | 4 |
| Array | 32-bit | 64-bit | |
|---|---|---|---|
Value* values |
Pointer to array of values (owned) | 4 | 8 |
SizeType size |
Number of values | 4 | 4 |
SizeType capacity |
Capacity of values | 4 | 4 |
unsigned flags_ |
kArrayType kArrayFlag |
4 | 4 |
| Number (Int) | 32-bit | 64-bit | |
|---|---|---|---|
int i |
32-bit signed integer | 4 | 4 |
| (zero padding) | 0 | 4 | 4 |
| (unused) | 4 | 8 | |
unsigned flags_ |
kNumberType kNumberFlag kIntFlag kInt64Flag ... |
4 | 4 |
| Number (UInt) | 32-bit | 64-bit | |
|---|---|---|---|
unsigned u |
32-bit unsigned integer | 4 | 4 |
| (zero padding) | 0 | 4 | 4 |
| (unused) | 4 | 8 | |
unsigned flags_ |
kNumberType kNumberFlag kUintFlag kUint64Flag ... |
4 | 4 |
| Number (Int64) | 32-bit | 64-bit | |
|---|---|---|---|
int64_t i64 |
64-bit signed integer | 8 | 8 |
| (unused) | 4 | 8 | |
unsigned flags_ |
kNumberType kNumberFlag kInt64Flag ... |
4 | 4 |
| Number (Uint64) | 32-bit | 64-bit | |
|---|---|---|---|
uint64_t i64 |
64-bit unsigned integer | 8 | 8 |
| (unused) | 4 | 8 | |
unsigned flags_ |
kNumberType kNumberFlag kInt64Flag ... |
4 | 4 |
| Number (Double) | 32-bit | 64-bit | |
|---|---|---|---|
uint64_t i64 |
Double precision floating-point | 8 | 8 |
| (unused) | 4 | 8 | |
unsigned flags_ |
kNumberType kNumberFlag kDoubleFlag |
4 | 4 |
Here are some notes: * To reduce memory consumption for 64-bit
architecture, SizeType is typedef as unsigned
instead of size_t. * Zero padding for 32-bit number may be
placed after or before the actual type, according to the endianness.
This makes possible for interpreting a 32-bit integer as a 64-bit
integer, without any conversion. * An Int is always an
Int64, but the converse is not always true.
Flags
The 32-bit flags_ contains both JSON type and other
additional information. As shown in the above tables, each JSON type
contains redundant kXXXType and kXXXFlag. This
design is for optimizing the operation of testing bit-flags
(IsNumber()) and obtaining a sequential number for each
type (GetType()).
String has two optional flags. kCopyFlag means that the
string owns a copy of the string. kInlineStrFlag means
using Short-String Optimization.
Number is a bit more complicated. For normal integer values, it can
contains kIntFlag, kUintFlag,
kInt64Flag and/or kUint64Flag, according to
the range of the integer. For numbers with fraction, and integers larger
than 64-bit range, they will be stored as double with
kDoubleFlag.
Short-String Optimization
Kosta provided a very
neat short-string optimization. The optimization idea is given as
follow. Excluding the flags_, a Value has 12
or 16 bytes (32-bit or 64-bit) for storing actual data. Instead of
storing a pointer to a string, it is possible to store short strings in
these space internally. For encoding with 1-byte character type
(e.g. char), it can store maximum 11 or 15 characters
string inside the Value type.
| ShortString (Ch=char) | 32-bit | 64-bit | |
|---|---|---|---|
Ch str[MaxChars] |
String buffer | 11 | 15 |
Ch invLength |
MaxChars - Length | 1 | 1 |
unsigned flags_ |
kStringType kStringFlag ... |
4 | 4 |
A special technique is applied. Instead of storing the length of
string directly, it stores (MaxChars - length). This make it possible to
store 11 characters with trailing \0.
This optimization can reduce memory usage for copy-string. It can also improve cache-coherence thus improve runtime performance.
Allocator
Allocator is a concept in RapidJSON: ~~~cpp concept
Allocator { static const bool kNeedFree; //!< Whether this allocator
needs to call Free().
// Allocate a memory block.
// \param size of the memory block in bytes.
// \returns pointer to the memory block.
void* Malloc(size_t size);
// Resize a memory block.
// \param originalPtr The pointer to current memory block. Null pointer is permitted.
// \param originalSize The current size in bytes. (Design issue: since some allocator may not book-keep this, explicitly pass to it can save memory.)
// \param newSize the new size in bytes.
void* Realloc(void* originalPtr, size_t originalSize, size_t newSize);
// Free a memory block.
// \param pointer to the memory block. Null pointer is permitted.
static void Free(void *ptr);}; ~~~
Note that Malloc() and Realloc() are member
functions but Free() is static member function.
MemoryPoolAllocator
MemoryPoolAllocator is the default allocator for DOM. It
allocate but do not free memory. This is suitable for building a DOM
tree.
Internally, it allocates chunks of memory from the base allocator (by
default CrtAllocator) and stores the chunks as a singly
linked list. When user requests an allocation, it allocates memory from
the following order:
- User supplied buffer if it is available. (See User Buffer section in DOM)
- If user supplied buffer is full, use the current memory chunk.
- If the current block is full, allocate a new block of memory.
Parsing Optimization
Skip Whitespaces with SIMD
When parsing JSON from a stream, the parser need to skip 4 whitespace characters:
- Space (
U+0020) - Character Tabulation (
U+000B) - Line Feed (
U+000A) - Carriage Return (
U+000D)
A simple implementation will be simply: ~cpp void
SkipWhitespace(InputStream& s) { while (s.Peek() == ’ ’ || s.Peek()
== ‘’ || s.Peek() == ‘ || s.Peek() ==’) s.Take(); }~
However, this requires 4 comparisons and a few branching for each character. This was found to be a hot spot.
To accelerate this process, SIMD was applied to compare 16 characters with 4 white spaces for each iteration. Currently RapidJSON supports SSE2, SSE4.2 and ARM Neon instructions for this. And it is only activated for UTF-8 memory streams, including string stream or in situ parsing.
To enable this optimization, need to define
RAPIDJSON_SSE2, RAPIDJSON_SSE42 or
RAPIDJSON_NEON before including rapidjson.h.
Some compilers can detect the setting, as in
perftest.h:
// __SSE2__ and __SSE4_2__ are recognized by gcc, clang, and the Intel compiler.
// We use -march=native with gmake to enable -msse2 and -msse4.2, if supported.
// Likewise, __ARM_NEON is used to detect Neon.
#if defined(__SSE4_2__)
# define RAPIDJSON_SSE42
#elif defined(__SSE2__)
# define RAPIDJSON_SSE2
#elif defined(__ARM_NEON)
# define RAPIDJSON_NEON
#endifNote that, these are compile-time settings. Running the executable on a machine without such instruction set support will make it crash.
Page boundary issue
In an early version of RapidJSON, an
issue reported that the SkipWhitespace_SIMD() causes
crash very rarely (around 1 in 500,000). After investigation, it is
suspected that _mm_loadu_si128() accessed bytes after
'\0', and across a protected page boundary.
In Intel® 64 and IA-32 Architectures Optimization Reference Manual, section 10.2.1:
To support algorithms requiring unaligned 128-bit SIMD memory accesses, memory buffer allocation by a caller function should consider adding some pad space so that a callee function can safely use the address pointer safely with unaligned 128-bit SIMD memory operations. The minimal padding size should be the width of the SIMD register that might be used in conjunction with unaligned SIMD memory access.
This is not feasible as RapidJSON should not enforce such requirement.
To fix this issue, currently the routine process bytes up to the next aligned address. After tha, use aligned read to perform SIMD processing. Also see #85.
Local Stream Copy
During optimization, it is found that some compilers cannot localize
some member data access of streams into local variables or registers.
Experimental results show that for some stream types, making a copy of
the stream and used it in inner-loop can improve performance. For
example, the actual (non-SIMD) implementation of
SkipWhitespace() is implemented as:
template<typename InputStream>
void SkipWhitespace(InputStream& is) {
internal::StreamLocalCopy<InputStream> copy(is);
InputStream& s(copy.s);
while (s.Peek() == ' ' || s.Peek() == '\n' || s.Peek() == '\r' || s.Peek() == '\t')
s.Take();
}Depending on the traits of stream, StreamLocalCopy will
make (or not make) a copy of the stream object, use it locally and copy
the states of stream back to the original stream.
Parsing to Double
Parsing string into double is difficult. The standard
library function strtod() can do the job but it is slow. By
default, the parsers use normal precision setting. This has has maximum
3 ULP
error and implemented in
internal::StrtodNormalPrecision().
When using kParseFullPrecisionFlag, the parsers calls
internal::StrtodFullPrecision() instead, and this function
actually implemented 3 versions of conversion methods. 1. Fast-Path.
2. Custom DIY-FP implementation as in double-conversion.
3. Big Integer Method as in (Clinger, William D. How to read floating
point numbers accurately. Vol. 25. No. 6. ACM, 1990).
If the first conversion methods fail, it will try the second, and so on.
Generation Optimization
Integer-to-String conversion
The naive algorithm for integer-to-string conversion involves division per each decimal digit. We have implemented various implementations and evaluated them in itoa-benchmark.
Although SSE2 version is the fastest but the difference is minor by
comparing to the first running-up branchlut. And
branchlut is pure C++ implementation so we adopt
branchlut in RapidJSON.
Double-to-String conversion
Originally RapidJSON uses snprintf(..., ..., "%g") to
achieve double-to-string conversion. This is not accurate as the default
precision is 6. Later we also find that this is slow and there is an
alternative.
Google’s V8 double-conversion implemented a newer, fast algorithm called Grisu3 (Loitsch, Florian. “Printing floating-point numbers quickly and accurately with integers.” ACM Sigplan Notices 45.6 (2010): 233-243.).
However, since it is not header-only so that we implemented a header-only version of Grisu2. This algorithm guarantees that the result is always accurate. And in most of cases it produces the shortest (optimal) string representation.
The header-only conversion function has been evaluated in dtoa-benchmark.
Parser
Iterative Parser
The iterative parser is a recursive descent LL(1) parser implemented in a non-recursive manner.
Grammar
The grammar used for this parser is based on strict JSON syntax: ~~~~~~~~~~ S -> array | object array -> [ values ] object -> { members } values -> non-empty-values | ε non-empty-values -> value addition-values addition-values -> ε | , non-empty-values members -> non-empty-members | ε non-empty-members -> member addition-members addition-members -> ε | , non-empty-members member -> STRING : value value -> STRING | NUMBER | NULL | BOOLEAN | object | array ~~~~~~~~~~
Note that left factoring is applied to non-terminals
values and members to make the grammar be
LL(1).
Parsing Table
Based on the grammar, we can construct the FIRST and FOLLOW set.
The FIRST set of non-terminals is listed below:
| NON-TERMINAL | FIRST |
|---|---|
| array | [ |
| object | { |
| values | ε STRING NUMBER NULL BOOLEAN { [ |
| addition-values | ε COMMA |
| members | ε STRING |
| addition-members | ε COMMA |
| member | STRING |
| value | STRING NUMBER NULL BOOLEAN { [ |
| S | [ { |
| non-empty-members | STRING |
| non-empty-values | STRING NUMBER NULL BOOLEAN { [ |
The FOLLOW set is listed below:
| NON-TERMINAL | FOLLOW |
|---|---|
| S | $ |
| array | , $ } ] |
| object | , $ } ] |
| values | ] |
| non-empty-values | ] |
| addition-values | ] |
| members | } |
| non-empty-members | } |
| addition-members | } |
| member | , } |
| value | , } ] |
Finally the parsing table can be constructed from FIRST and FOLLOW set:
| NON-TERMINAL | [ | { | , | : | ] | } | STRING | NUMBER | NULL | BOOLEAN |
|---|---|---|---|---|---|---|---|---|---|---|
| S | array | object | ||||||||
| array | [ values ] | |||||||||
| object | { members } | |||||||||
| values | non-empty-values | non-empty-values | ε | non-empty-values | non-empty-values | non-empty-values | non-empty-values | |||
| non-empty-values | value addition-values | value addition-values | value addition-values | value addition-values | value addition-values | value addition-values | ||||
| addition-values | , non-empty-values | ε | ||||||||
| members | ε | non-empty-members | ||||||||
| non-empty-members | member addition-members | |||||||||
| addition-members | , non-empty-members | ε | ||||||||
| member | STRING : value | |||||||||
| value | array | object | STRING | NUMBER | NULL | BOOLEAN |
There is a great tool for above grammar analysis.
Implementation
Based on the parsing table, a direct(or conventional) implementation that pushes the production body in reverse order while generating a production could work.
In RapidJSON, several modifications(or adaptations to current design) are made to a direct implementation.
First, the parsing table is encoded in a state machine in RapidJSON.
States are constructed by the head and body of production. State
transitions are constructed by production rules. Besides, extra states
are added for productions involved with array and
object. In this way the generation of array values or
object members would be a single state transition, rather than several
pop/push operations in the direct implementation. This also makes the
estimation of stack size more easier.
The state diagram is shown as follows:
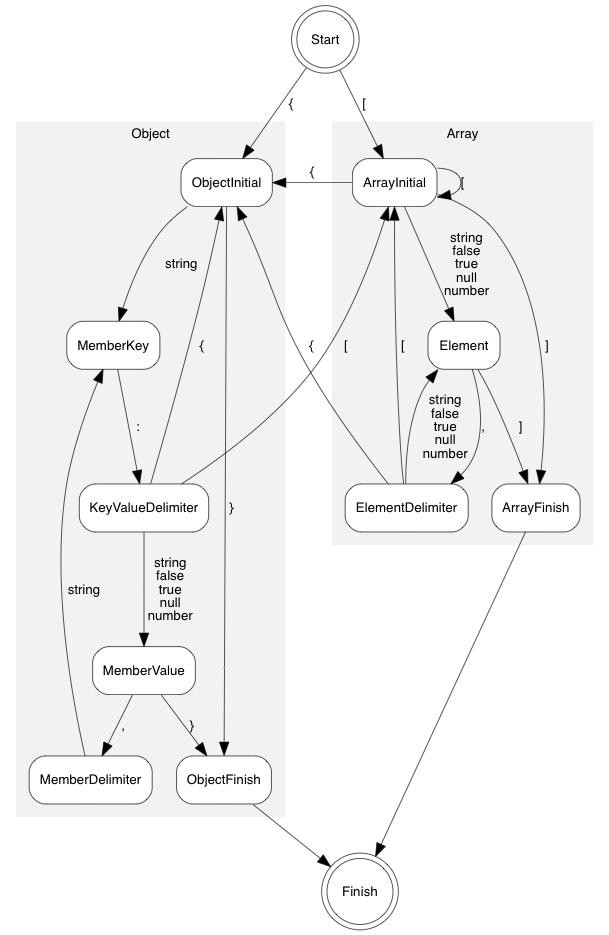
Second, the iterative parser also keeps track of array’s value count and object’s member count in its internal stack, which may be different from a conventional implementation.